GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Motivation
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, i.e., the "label rendering" task, to build semantic NeRFs.
However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object.
Proposed Solution
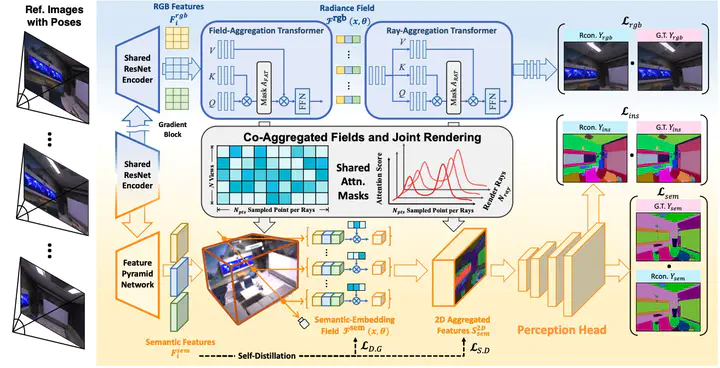
To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception.
To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields.
In addition, we propose two self-distillation mechanisms:
1. Semantic Distill Loss: Enhances the discrimination and quality of the semantic field.
2. Depth-Guided Semantic Distill Loss: Maintains geometric consistency between radiance and semantic fields.
Experimental Results
In evaluation, we conduct experimental comparisons under two perception tasks (i.e., semantic segmentation and instance segmentation) using both synthetic and real-world datasets.
Notably, our method outperforms SOTA approaches by:
• 6.94% on generalized semantic segmentation
• 11.76% on finetuning semantic segmentation
• 8.47% on instance segmentation
These significant improvements demonstrate the effectiveness of GP-NeRF in bridging the gap between neural radiance fields and context-aware perception, enabling more accurate and consistent 3D scene understanding.